
AWS podría volver a caerse: actualizaciones en vivo tras una interrupción masiva que interrumpió Internet
https://www.tomsguide.com/news/live/amazon-outage-october-2025
En la madrugada del 20 de octubre, Amazon Web Services sufrió una interrupción que duró varias horas y afectó a numerosos sitios web, aplicaciones y plataformas. A lo largo del día se implementaron varias soluciones, aunque las interrupciones continuaron afectando a una amplia gama de servicios, desde aplicaciones bancarias hasta plataformas de formación universitaria, entre otros.
En total, los informes de Downdetector alcanzaron un máximo de más de 50 000 desde alrededor de las 7:50 a. m.
Para quienes no lo sepan, AWS es la columna vertebral de internet y actúa como infraestructura para aplicaciones y sitios web como Snapchat, Venmo, Ring, Pokémon GO y otros, que sufrieron caídas debido a la interrupción de AWS.
En concreto, un centro denominado Región US-EAST-1 se cayó, afectando a los residentes de la costa este y a cualquier servicio basado en infraestructura fuera de la región.
Seguimos la interrupción recopilando información de varios servicios, buscando detalles sobre cuándo se podría implementar una solución y solicitando comentarios de Amazon.
A pesar de varias correcciones reportadas por AWS, la implementación fue lenta y las reparaciones tomaron tiempo.
En total, la mayor parte de la interrupción duró más de 12 horas, comenzando a la 1 a. m., hora del Pacífico, y se extendió hasta las 3 p. m., hora del Pacífico. Para entonces, no había terminado del todo, pero los servicios parecían estar volviendo a estar en línea con mayor funcionalidad.
Como parte de nuestra cobertura, analizamos todas las aplicaciones y servicios afectados por la interrupción (y estamos seguros de no haberlos detectado a todos), así como cómo se produjo la interrupción y por qué interrumpió internet. Los lectores atentos señalaron servicios con fallas como Canvas para estudiantes universitarios y aplicaciones para pequeñas empresas como Shopify y ShipStation, que estaban afectando a empresas y centros educativos.
Por otra parte, monitoreamos Snapchat y Venmo, ya que ambos servicios parecen estar totalmente fuera de servicio y fueron los que recibieron la mayor cantidad de reportes.

Podrían ser simplemente correcciones que AWS está aplicando sobre la marcha, pero no esperamos que se extiendan tanto como ayer. Estaremos atentos.
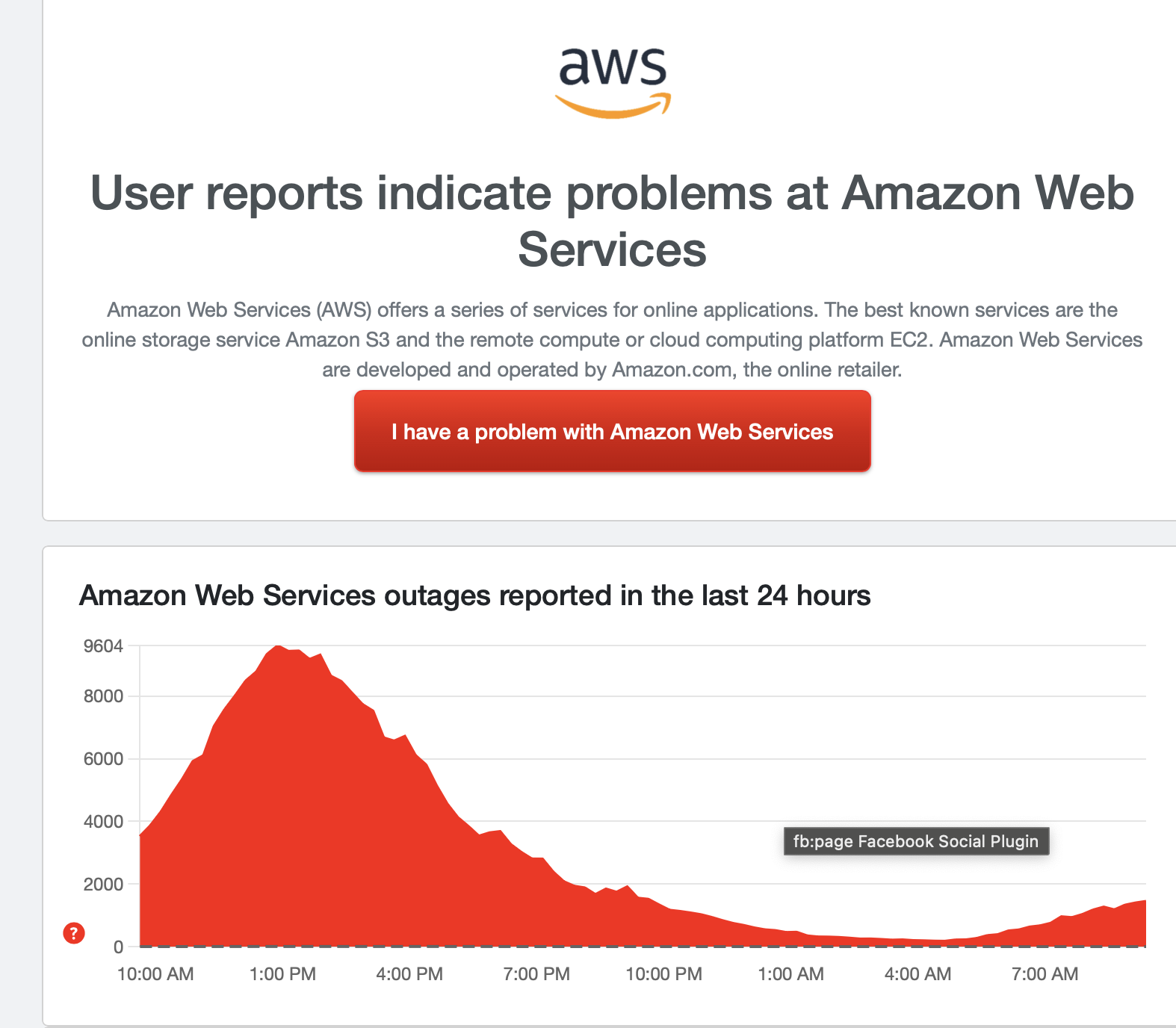
Los informes de AWS sobre Down Detector se mantienen prácticamente estables. Sigue siendo una cantidad elevada de informes (1447 al momento de esta publicación), pero no se compara con los de ayer, cuando los informes alcanzaron las decenas de miles. Seguiremos monitoreando la situación para ver si empeora, pero por ahora parece que estamos atrapados entre una interrupción total y un pequeño error.

Actualmente, estamos observando problemas de red en Fráncfort. Por si no lo sabían, Cloudflare se usa a menudo con AWS, lo que podría ser otra señal de que no todo va bien en Amazon Web Services, pero tendremos que esperar.
Pueden leer más sobre la situación de Cloudflare en la página de estado, pero es, cuanto menos, preocupante.
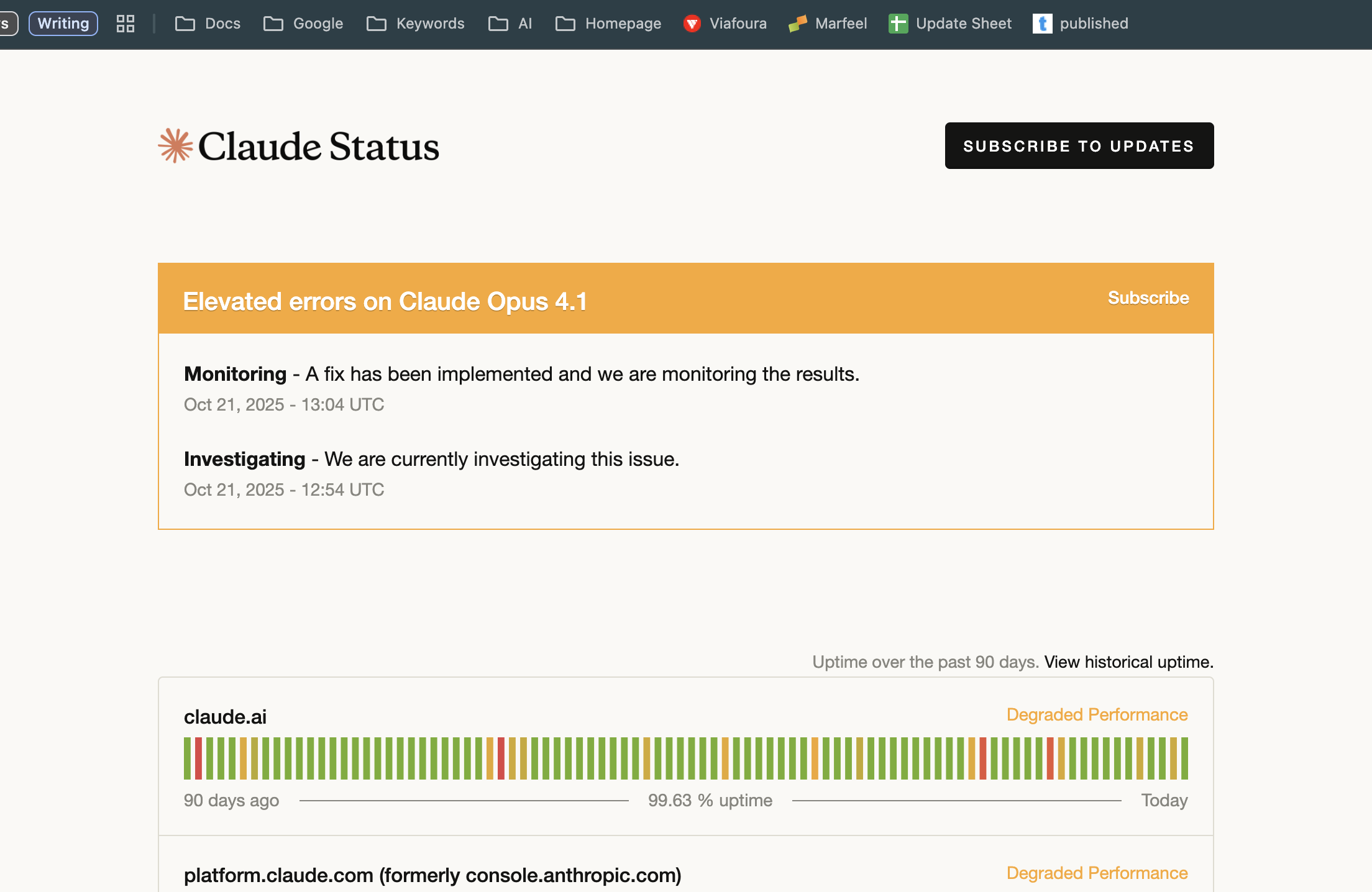
Como sabemos, cuando AWS se cae, gran parte de internet también. Por eso, no sorprende que la página de estado de Anthropic muestre una interrupción de Claude. ¿Se producirán más interrupciones? Depende de si AWS solo está experimentando un pequeño problema o si se está produciendo una segunda ronda de interrupciones masivas.
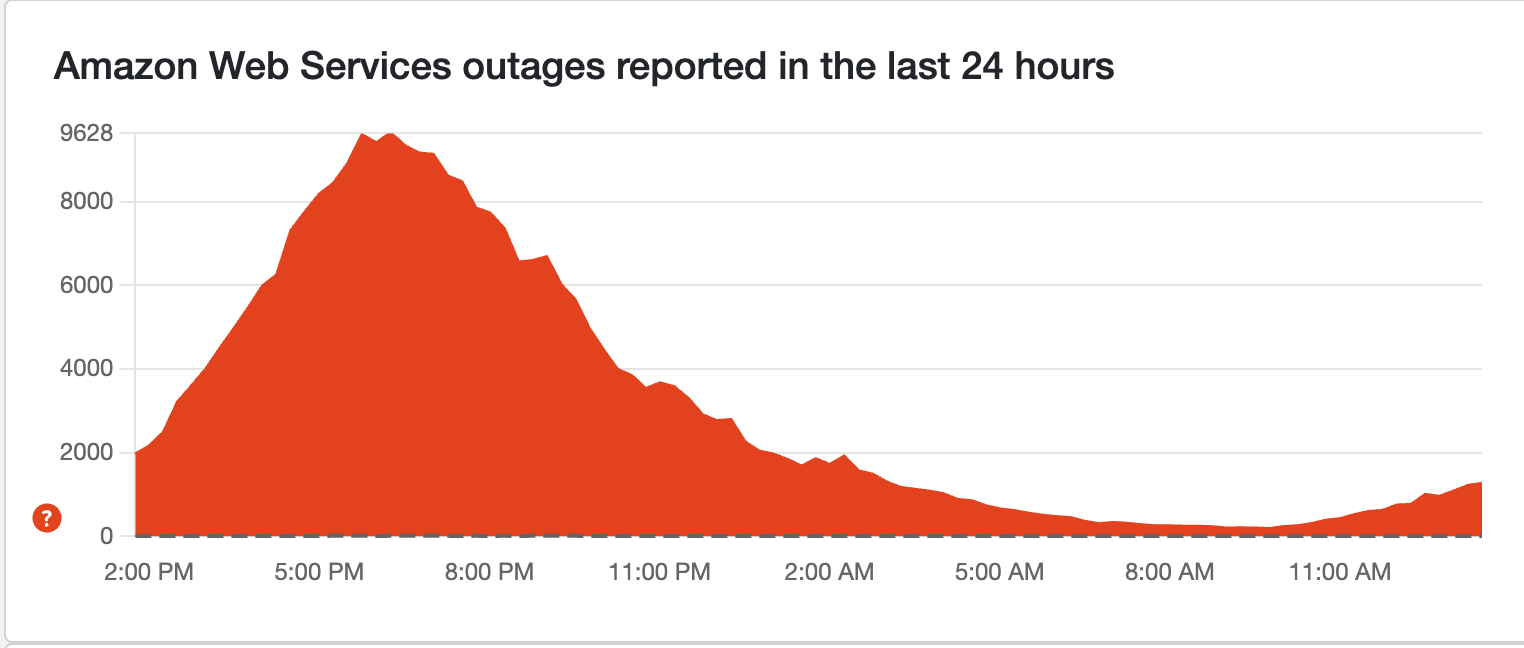
AWS se cayó ayer debido a un problema de DNS que se extendió a servicios de todo el planeta. Supuestamente se solucionó ayer, pero esta mañana han vuelto a aparecer informes en Down Detector.
Y nunca adivinarás quién es el culpable... sí, es US-EAST-1 otra vez. Ya he escrito sobre este problema clave, ya que gran parte de internet depende de una sola región de servidores.
¿Serán trolls atacando Down Detector para provocar problemas en internet o algo más grave? Los mantendremos informados.
No hay comentarios:
Publicar un comentario